










Sử dụng Weka trong xây dựng mô hình phân lớp dữ liệu
trong xây dựng mô hình phân lớp dữ liệu
trong xây dựng mô hình phân lớp dữ liệu1. Tóm lược lý thuyết về phân lớp (Classification
 )
)Trong lĩnh vực máy học (machine Learning) và nhận dạng (pattern recognition), bài toán phân lớp (classification) đề cập đến các thuật toán (algorithms) nhằm xác định lớp (class) của đối tượng đã cho sẽ thuộc về lớp nào trong các lớp đã cho trước (Given Categories). Một điều cần chú ý là khác với bài toán phân cụm (clustering), dữ liệu dùng để xây dựng mô hình (Training Data) trong bài toán phân lớp phải được xác định lớp trước (pre-Labeled).
Ví dụ, xác định một email thuộc “spam” hoặc “non-spam”, hay xác định loại bệnh của bệnh nhân dựa vào các triệu chứng của họ.
Một thuật toán thực hiện việc phân lớp được gọi là bộ phân lớp (classifier). Hình sau mô tả qui trình xây dựng mô hình phân lớp các đối tượng.

Qui trình Train và Test một classifier
- Dữ liệu để xây dựng mô hình: dữ liệu gốc (original dataset), dữ liệu này phải có thuộc tính phân lớp gọi là categorical attribute
- Dữ liệu gốc sẽ được chia thành 2 phần là Training Set (để xây dựng model) và Testing Set (để kiểm định Model)
- Cuối cùng là tính toán lỗi để đánh giá Model


Cross Validation (CV) trong Training and Testing Phase
Đây là kỹ thuật chủ yếu được sử dụng trong xây dựng predictive Model. Trong đó dữ liệu gốc sẽ được chia thành n phần bằng nhau (n-fold), và quá trình Train/Test Model thực hiện lặp lại n lần. Tại mỗi lần Train/Test Model, 1 phần dữ liệu dùng để Test và (n-1) phần còn lại dùng để Train.
(Người ta đã chứng minh 10-fold Cross –Validation là tối ưu)
Hình dưới đây mô tả CV với 3-fold.

Hình dưới đây mô tả 10-fold Cross Validation của Iris Dataset.
Iris dataset là bộ dữ liệu về hoa dung để kiểm tra các classification models.
Iris Dataset gồm 150 samples (instances), thuộc 3 lớp (classes| categories) là setosa, vesicolor và virginica, mỗi lớp có 50 samples
Cấu trúc của Iris dataset như sau:
Attributes x Instances = 5 x150
Number of classes : 3
Distribution for each class : 50 (mỗi lớp có 50 instances)
Số thuộc tính là 5, trong đó có 1 thuộc tính phân loại có tên class (categorical Attribute)
Sepallength: Độ dài đài hoa
Sepalwidth: Độ rộng đài hoa
Petallength: Độ dài cánh hoa
Petalwidth: Độ rộng cánh hoa
Class: thuộc tính phân loại hoa (setosa, vesicolor và virginica)
Xem và download Iris dataset và nhiều dataset khác theo link dưới đây
http://archive.ics.uci.edu/ml/datasets/Iris

2. Thực hiện bài toán phân lớp với Weka
Phần này trình bày xây dựng mô hình phân lớp với phần mềm Weka, trên bộ dữ liệu hoa Iris đã giới thiệu ở trên
Download Weka tại đây [Lưu ý: sau 5s, click BỎ QUA QUẢNG CÁO (SKIN AD)]

Chọn tab: Prerprocess để thực hiện các bước tiền xử lý trong data Mining như (Load data, Filter, …)
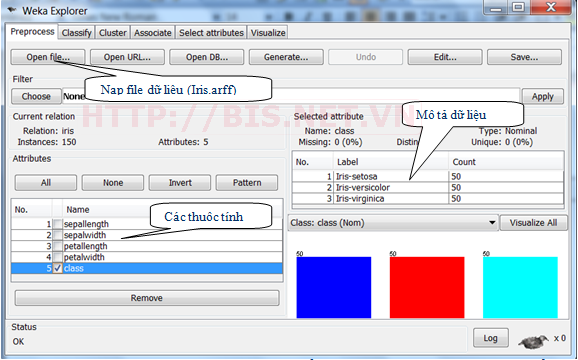
Sau khi nộp dữ liệu, chọn Tab classify để chọn các mô hình phân loại. Ở đây ta sẽ sử dụng và so sánh hiệu quả của 2 mô hình phân lớp của cây quyết định (Decision tree) là J48 và SimpleCART và mô hình MultilayerPerceptron của mạng Neuron (Neural network)


Chú ý: Việc lựa chọn thuật toán nào để có một model tốt phụ thuộc rất nhiều yếu tố, trong đó cấu trúc của dataset có ý nghĩa quan trọng đến việc lựa chọn thuật toán. Ví dụ thuật toán cây hồi qui phân loại (CART – Classification And Regression Tree
 ) và J48 cho kết quả tốt trên các dữ liệu kiểu số (Numerical Data), trong khi đó thuật toán ID3 cho kết quả tốt đối với dữ liệu định danh (nominal Data).
) và J48 cho kết quả tốt trên các dữ liệu kiểu số (Numerical Data), trong khi đó thuật toán ID3 cho kết quả tốt đối với dữ liệu định danh (nominal Data).
0 comments:
Post a Comment